ECE 743 Power Aware Computing
Project:
Dynamic speed/voltage
scaling for GALS processors
Shelley Chen Anand Eswaran
Department of Electrical and Computer
Engineering
Email: {schen1, aeswaran}@andrew.cmu.edu
 Overview:
Overview:
Dynamic voltage scaling (DVS) has emerged
as a successful and scalable solution to deal with the growing power
consumption associated with increased chip complexity. However, DVS is not very
effective when used with synchronous processors, as the performance of them is
totally dependent upon the speed of the clock.
Higher clocking consumes a great deal of power while lower clocking will
degrade performance significantly. Thus,
we?ve decided to use Globally Asynchronous, Locally Synchronous
processors. These allow for selective
clocking of different components of the system.
Clocking can thus be chosen in such a way as to minimize performance
degradation.
We describe two schemes that allow the
extension of DVS across multiple clock domains specific to GALS out-of-order superscalar
processors. One scheme addresses the issues involved in the commonly shared
front end of the pipeline. The other enhances the effectiveness of voltage
scaling within the various functional units of a superscalar processor by
addressing dependency issues.
We plan to implement our design on by
modifying simGALS, a GALS simulator and power estimator designed by Iyer and
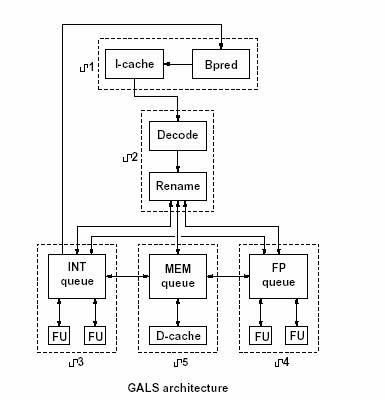
Marculescu [1]. The architecture of the
GALS processor is shown in the figure at the left.
Project Proposal:
As the scope of our project
changed since, the proposal presentation, the information in the proposal
slides is not relevant anymore. Thus,
unless specifically requested, the slides from the proposal presentation will
not be put up on the website because they are irrelevant to this project. The write up, however, was corrected in
time. The link is below.
Project Checkpoint 1:
Presentation
slides for Checkpoint 1
Key points:
1.
Front end
adaptive scaling
·
Control the clock
speed of the front end of the system (fetch and decode stages) based on commit
rate. The commit rate should be as close
as possible to the fetch rate
·
Certain variables
need to be considered including window size, thresholds and amount of speedup
or slowdown of the fetch rate clock when needed.
2.
Dependency based
adjustments
·
Since clock
adjustments for the functional units are currently solely based on queue
length, it can cause inefficient use of resources by speeding up functional
units whose queues are filled with instructions waiting for dependencies.
·
We would like to
change this so that the clock rate of each functional unit is based on the
number of instructions that have no dependencies in the queue, rather than just
the number of instructions.
·
This prevents
unnecessary speedups, reducing wasted power consumption.
Accomplishments:
·
Familiarized
ourselves with simGALS.
·
Implemented the
module for calculating the commit and fetch rates of the asynchronous
processor.
·
Currently
implementing the slowdown of the fetch stage.
·
Identified the
dependencies that we need to deal with for the dependency based adjustments of
the functional unit clock
Project Checkpoint 2:
Presentation
slides for Checkpoint 2
Accomplishments:
·
Implemented
throttling of the front end of the pipeline.
·
Determined most
of the values for variables of the implementation through simulations.
o
Optimal window
size: 152
o
Optimal lower
threshold: -3
o
Optimal clock
period: 1.
·
We still need to
determine the high threshold value by running more simulations.
Project Checkpoint 3:
Presentation slides for Checkpoint 3
Accomplishments:
We
developed the algorithm and tested the algorithm for front-stage dynamic voltage
scaling based on fetch rate commit rate matching in Milestone 2. In milestone
3, we concentrate on enhancing the DVS algorithm for functional units that is
proposed by [1] to account for data dependencies.
The
rationale behind the scheme of dynamic voltage scaling lies in the fact it is
possible to achieve significant energy savings without significant performance
degradation if the net throughput demand for the resource (functional unit) is
relatively low. This energy reduction is
obtained by reducing the processor speed and scaling the voltage
correspondingly.
In
[1] and [2], the authors use queue length as a metric of the required speed-up
of a functional unit. Thus if a functional unit (FU) has a large number of
instructions in its issue queue, it indicates that there are a large number of
instructions waiting for it and hence it probably lies on the critical path of
instruction flow. Thus it should not be slowed down.
However,
we believe that having the frequency track the envelope of the functional unit
queue length over long periods of time has it drawbacks. This is because of
data dependencies across functional units. In particular, instructions might be
blocked in the issue queue because they depend on instructions ahead in the
issue queue while the instruction at the head is blocking on output from some
other functional unit. In this scenario,
speeding up the functional unit based on an increased queue occupancy
results in high energy loss ( due to high clocking ) while little performance
benefit. Thus the original algorithm
would benefit greatly if it took into account cross functional-unit data
dependencies.
We
propose a change to the algorithm proposed in [1] based on our observations. We
propose that the scaling be based upon two factors:
(1)
The dependant-free (independent) instructions in each queue
(2)
The total number of direct dependencies on each functional unit. The modified algorithm we propose is given
below:
if (state == HIGH_STATE) {
if (independent instructions in queue < threshold) increment
count;
if (count
> CLOCK_INTERVAL) state = LOW_STATE;
}
else // state == LOW_STATE
{
if (
independent instructions in the queue < threshold) OR ( direct dependency count > dep_threshhold
) increment count;
if (counter <
CLOCK_INTERVAL) state = HIGH_STATE;
}
Hardware Details:
Our strategy for tracking the dependent
count and independent count of each functional unit is simple and
computationally efficient.
We associate two counters (as opposed to one
counter used in [1]) with each functional unit. One of these keeps track of the
independent instructions and another keeps track of the dependent instructions
associated with each FU. By judiciously choosing the parameters of this scheme
we believe that we can achieve a good energy-performance balance.
Implementation in SimGALS:
Just prior to the issue stage of each
functional unit, we check if the instruction entering the issue queue has any
dependency associated with it. If it does not, we increment the functional
unit?s independent counter. Else we
increment the counter associated with
the source of the dependency.
During the commit back stage the following
operations take place. Firstly the committing instruction wakes up all issue
queue entries associated with that functional unit based on the output produced by that
functional unit. Secondly it puts it?s result on the
queues of other associated functional units. Thirdly it reads results produced
by other functional units and wakes up instructions in its issue queue that
were dependant on these functional units. We increase the independent counters
of the FU?s by the number of instructions woken up by the first and third
stages.
The decrementing of the dependant counters
takes place just before the second step. Here the instruction decrements the
dependent count of the current functional unit by one for each instruction that
resides in another functional unit queue which the current FU?s result wakes
up.
When the result is finally retired to the
register file, the independent count is decreased by one.
Project Checkpoint 4:
Presentation slides for Checkpoint 4
Accomplishments:
For this checkpoint, we were able to
fix that horrible counter problem that we were not able to resolve from the
last Milestone. In addition, currently,
we believe that we have found the best configuration for the functional units
of the simulator. However, we have not
delved into the configuration of the front end of the simulator and assumed
that the two modules were orthogonal.
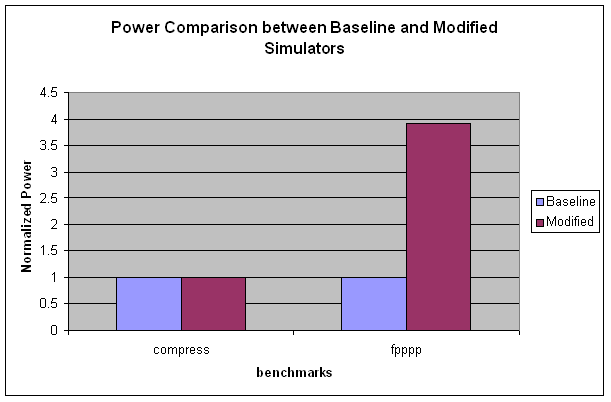
However, results seem to prove otherwise. Our power consumption is not lower than the original
baseline model, as expected. In fact,
for the fpppp benchmark, the power values are almost 4 times higher than the
baseline! This is definitely a problem
that we have to look further into. This
will be the problem that we need to resolve soon.
Results from this Milestone:
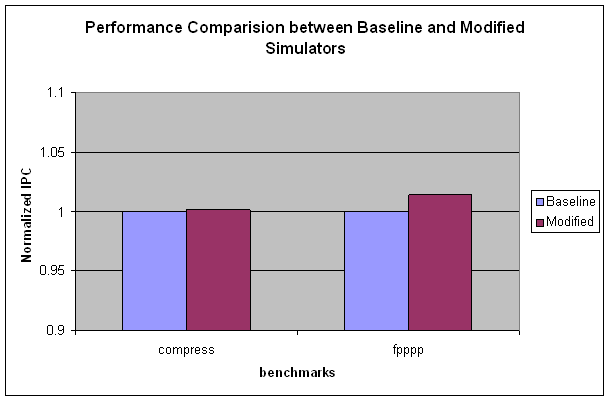
Final Project Checkpoint:
Presentation
slides for Final Project
Accomplishments:
·
Finally got the
simulator working!
Results:
·
60% savings in
power and 15% savings in Energy
·
See the writeup for a more complete description of the results.
Source Code:
·
The AFS location
of our modified code for the project is at /afs/ece/usr/schen1/sim-GALS. This code will be continually updated as work
progresses on this project.
Related Research Papers:
1. A. Iyer and D. Marculescu. Power-Performance
Evaluation of Globally Asynchronous, Locally Synchronous Processors. Intl.
Symposium on Computer Architecture (ISCA).
May 2002.
2. A. Iyer and D. Marculescu. Power Efficiency of
Multiple Clock, Multiple Voltage Cores. IEEE/ACM
Intl. Conference on Computer-Aided Design (ICCAD). Nov. 2002.
3. G. Semeraro, D.H. Albonesi, S.G. Dropsho, G. Magklis, S. Dwarkadas, and M.L.
Scott. Dynamic Frequency and Voltage Control for a Multiple Clock Domain Microarchitecture.
35th International Symposium on Microarchitecture.
November 2002.
4. G. Semeraro, G. Magklis, R. Balasubramonian, D.H. Albonesi, S. Dwarkadas,
and M.L. Scott. Energy-Efficient Processor Design Using
Multiple Clock Domains with Dynamic Voltage and Frequency Scaling. 8th International Symposium on
High-Performance Computer Architecture. pp. 29-40, February 2002.
5. A. Moshovos, D. N. Pnevmatikatos and A. Baniasadi. Instruction Flow-based
Front-end Throttling for Power-Aware Higher-Performance Processors. Proc.
International Conference on Supercomputing (ICS), June 2001.
6. D. Burger, T. Austin. The SimpleScalar Tool Set, Version 2.0. Technical Report CS-TR-97-1342. University of Wisconsin, Madison, Wisconsin, June 1997.
Questions? Please contact schen1@ece.cmu.edu