| MEAD User Manual
Version 1.0 May 28, 2004 By downloading this software the user agrees
to accept this software entirely as is, with absolutely no
warranty whatsoever, expressed or implied. The responsibility
for ensuring fitness and correctness for any purpose lies
entirely with the user. Questions about this document to be sent
to mead-support@lists.andrew.cmu.edu
The Middleware for Embedded Adaptive Dependability (MEAD) infrastructure aims to enhance distributed real-time middleware applications with new capabilities including:
More information, including publications on the MEAD system, can be found at the MEAD website. This release of MEAD focuses on non-adaptive replication, i.e., the replication style does not change on the fly. Given the current state-of-the-art in ORBs, which are not completely stateless black-boxes, the unit of replication (also known as a replica) is effectively the process or the container, and not the individual object or the component. Note that replicating processes automatically replicates the components/objects hosted within those processes. The replication styles currently offered by MEAD are active replication and warm passive replication. Active replication (see figure immediately below) allows multiple replicas when spawned, to join a replica group. Each individual replica processes each invocation and sends results back to the client. The beauty lies in the fact that MEAD suppresses duplicate responses, and the client believes it is communicating with a single server. Checkpoints (i.e., state snapshots) are triggered in active replication only when a new replica is launched and needs to synchronize its state with those of the other running replicas. 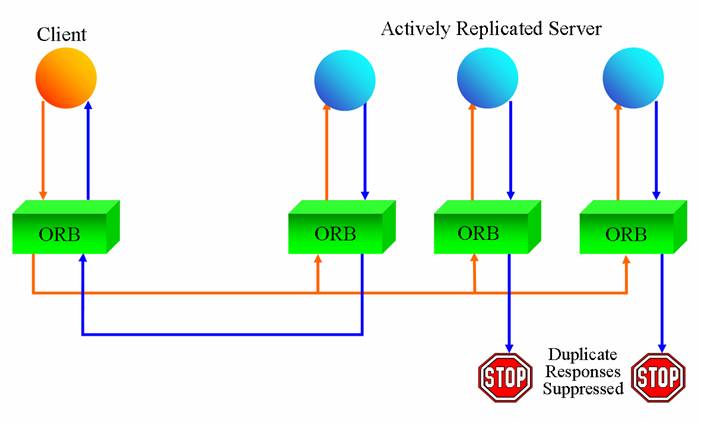
Warm passive replication (see figure immediately
below) designates one replica to be the primary and the others to be
backups, in the event of the primary's failure. Only the primary replica
processes invocations from the client and responds to the client. All
backups in the replica group periodically receive checkpoints from the
primary that allow them to synchronize their respective states with that
of the primary. 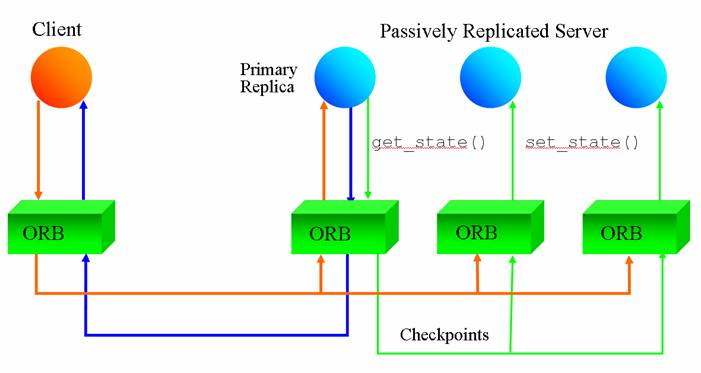
Both replication styles offer fault tolerance through
redundancy. Active replication can be resource intensive (because of
increased CPU usage and bandwidth usage), but provides faster response and
recovery times. On the other hand, warm passive replication typically
conserves resources, but the response time is bounded by the network and
processing speed of the primary replica. Also, increased bandwidth and CPU
usage might result if the size and frequency of checkpoints is
sufficiently large. Warm passive replication's recovery times are also
slower because the recovery time includes failover time from the crashed
primary to the backup. Currently Supported Configurations Emulab is the distributed test-bed of choice for the MEAD system. If you have never used Emulab before, please refer to the Emulab "Getting Started" Tutorial. More details to get MEAD running on Emulab can be found in the Running MEAD on Emulab section. The current version of MEAD supports, and has been tested with, the following platforms, ORBs and third-party software. Platforms: Red Hat Linux 9 (The BBN-RH9-SS7-8 image on Emulab). MEAD uses the Spread group communication system for inter-object communication. More details can be found below under the Running and Configuring Spread section. DistributionThe directory containing the latest release of the MEAD software distribution is located on Emulab at /groups/pces/uav_oep/mead_cmu/release/mead. The current MEAD release is comprised of library code for
the MEAD replication mechanism, pre-built Spread libraries for Red Hat 9,
a stateful CORBA application in the counter
directory and a stateless CORBA application in the stateless directory, a readme file, makefiles, and
scripts for execution. MEAD is comprised of the following directory
structure: The replication directory contains the mead library and replication mechanism. The directory spreadlinuxbin contains the pre-built Spread libraries. Finally, the scripts directory contains bash scripts that can be used to load and run the sample CORBA applications. Known Caveats and RecommendationsThe current version of MEAD provides support for CORBA clients to discover servers through the Interoperable Object Reference (IOR) mechanism. The server outputs its IOR into a file that the client can subsequently read, in order to connect to the server. Future versions of MEAD will support the use of the CORBA Naming Service in order for clients to discover servers. In the interests of fault containment and effective replication, we recommend hosting only one replica of a server per node. While it is possible to host more than one server replica per node, if the node is to contain the fault, and a single processor-crash should not affect more than one replica, running only one replica of a server process per node is ideal. The current version of MEAD requires the CORBA application to be deterministic in behavior, i.e., any two replicas of the server, when starting from the same initial state, and receiving the same set of invocations in the same order, should reach the same final state. This eliminates the use of local timers, shared memory and any other OS primitive that can lead to irreproducible behavior across different nodes in a distributed system. Determinism is a common assumption in the development of fault-tolerant distributed systems; while ongoing development in the MEAD project aims to eliminate the need for determinism, the current version of the MEAD requires this of the application. Reporting Problems & Obtaining SupportIf you face a specific problem with running or installing the MEAD system, please fill out the details of the problem using the Support Request Form. For more general questions on MEAD, please email us at mead-support@lists.andrew.cmu.edu CORBA Application Requirements In order to restore application-level state in
the event of a server crash, the Fault-Tolerant
CORBA standard requires every CORBA object to support an
additional Checkpointable interface,
with methods for the retrieval and assignment of
application-level state. This interface is an abstract class and
can be inherited by the application when working with MEAD. Note
that State can be defined in a custom
way, based on the CORBA object's state. MEAD simply invokes these
methods in order to perform checkpointing and state transfer for
both warm passive and active replication. After implementing
these functions, the application programmer does not need to
worry further about them (except, of course, for updating the
implementations of these methods should the application's
definition of state change) MEAD handles ORB-level and
infrastructure-level state so that the application programmer
does not need to worry about them.. When developing CORBA applications for MEAD, it is necessary to implement get_state() and set_state() at the object level, and get_global_state() and set_global_state() for void pointer data at the application level (extern functions). At the application level, the example below
uses void pointers to offer a less
restrictive implementation. The data type state can be any type of structure
containing all of the current state for the process as well as
CORBA object state from above. This C code can be used to
declare the external functions for get_global_state() and set_global_state(): The MEAD library (libmead.so) requires both ACE/TAO and Spread to function. These must be installed and correctly configured prior to building MEAD. More details can be found at the TAO main website and Spread website, respectively. Documentation and tutorial information on TAO development can be found at the TAO development website. Makefiles tailored to BBN-RH9-SS7-8 are included in the replication, stateless, counter, and the scripts directories. The makefiles found in the counter and stateless directories build client and server CORBA applications. The replication directory's makefile will build the MEAD library as well as a timing library that can be used for empirical evaluation. The scripts directory supports a "make clean" option to remove any unnecessary remnants caused by IOR files. Before running make, remember to "source source_this_for_Emulab" at the root of the MEAD distribution. The replication makefile makes use of the Spread library (libspread.so) found in the spreadlinuxbin directory. If not using Red Hat 9 it will be necessary to install and configure Spread on your target platform. For convenience this MEAD distribution includes pre-built Spread binaries in the spreadlinuxbin directory. Finally, both the sample CORBA applications as well as the replication library makefiles can compile the target application in debug mode. This will enable the inner workings of the replication library as well as the CORBA applications to be viewed from the standard output. To enable debugging, look for the mINCLUDES (counter/stateless) or CPPFLAGS (replication) variable that enables debugging in the respective makefiles. They should be preceded by a comment about debugging and will essentially enable -DDEBUG. Running and Configuring Spread Spread Overview Spread is a group communication system developed at John Hopkins University and currently developed by Spread Concepts LLC and CNDS at John Hopkins University. Additional information can be found at the Spread website as well as the Spread User Manual. The Spread daemon can be launched using this command:
The Spread configuration file contains options for the Spread daemon, and comments on the configuration of each option. MEAD is mostly concerned with the Spread_Segment { }, which contains a list of <hostname> <IP> pairs for each node in the cluster, as well as a broadcast address and port for execution. The following is a sample configuration file used in the Emulab environment. The broadcast address can differ in range (i.e., in the first three dotted-decimal places) from the IP addresses of the three nodes; this is specific to the Emulab environment where the nodes seem to be multi-homed. The broadcast is for local connectivity and the individual host IPs are actual addresses that can be resolved for the machine. Spread_Segment BroadcastAddress:SpreadPortNumber
{ Finally, only use the computer name for the <Hostname> parameter and not the fully qualified name for the computer (e.g. use node0 not node0.test.pces.emulab.net). When compiling the Spread library and the Spread daemon, there is a series of timeouts that can be set can be configured and compiled. These can significantly affect the performance of both Spread and MEAD. More details can be found in the Spread User Manual. The following lists a few common errors related to configuration of spread that are returned from the MEAD library, more details can be found at: http://www.spread.org/docs/docspread.html
The primary test-bed for MEAD software is Emulab. The sequence of steps below details a run using the BBN-RH9-SS7-8 Emulab image. This run will replicate three servers in either active or warm passive replication styles (you can configure your choice) and will use a single client to make requests of the three-way replicated server. Some of the following steps need to be executed on every assigned Emulab node (step is prefaced by [every node]) or only on one assigned Emulab node (step is prefaced by [one node]). The symbol % represents the shell command-line prompt.
Here are common things to watch out for, when running MEAD:
The MEAD library uses several environmental variables for
configuration. The following table offers the names and descriptions of
the variables as well as acceptable values.
MEAD will run in other environments that have configured functional copies of both ACE/TAO and Spread. The examples above should work as well provided that:
Contributors to MEAD include Priya Narasimhan, Tudor Dumitras, Aaron
Paulos, Soila Pertet, Charlie Reverte, Joe Slember and Deepti Srivastava.
|
|||||||||||||||||||||||||||||||||||||||||||||