Team 2: The House
18-749: Fault-Tolerant Distributed Systems
Spring 2006
|
|
|
Paul |
Mo |
Jun |
Suk Chan |
Joohoon |
Baseline Application |
x |
|
|
|
|
Project Management & Webmastering |
x |
|
|
|
|
Fault-Tolerance: Client |
x |
x |
|
|
|
Fault-Tolerance: Evaluation Lead |
|
|
|
|
x |
Fault-Tolerance: Replication Management and Fault Detection |
|
|
x |
x |
|
Architecture
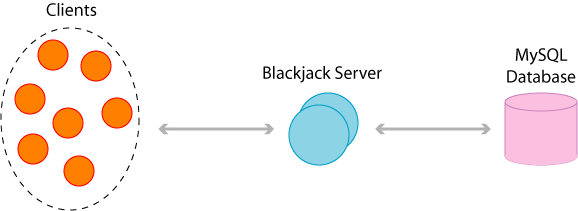

HostBean (session): Every request from the client goes through this bean, including saving/retrieving profiles.
FloorBean (entity): This bean represents the floor of our casino. It has a one-to-many CMR with TableBean.
TableBean (entity): This bean represents a Blackjack table. It has a one-to-many CMR with PlayerBean. It keeps track of the deck, and is responsible for passing around the turn.
PlayerBean (entity): This bean represents the profile of a player. It keeps track of cards he's holding, current balance, name, ID, and password.

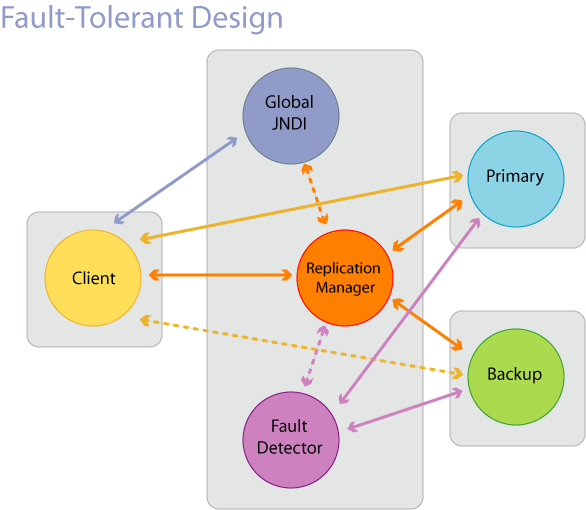
Each replica, as it starts, notifies the replication manager of its presence and sends its JNDI address. The replication manager keeps track of alive/dead replicas. After being notified of a new replica's presence, the replication manager notifies the fault detector, which communicates with local fault detectors on the replicas. The local fault detector is used to detect process failures, while the (global) fault detector is used to detect machine failures and notify the replication manager of process/machine failures. When a client gets an exception and fails over, it asks the replication manager for a new primary.
* No checkpointing and state transfer is necessary for now since our servers are completely stateless.
* Each client will have a unique ID and an operation ID for each state-changing invocation to avoid duplicate state changes.
* The operation ID will increment with each method invocation that changes state. Both unique ID and operation ID are kept in the database.
1. There is one active primary, and one warm-passive backup, named 'server1' and 'server2' respectively.
2. The client starts and looks up available servers in the global JNDI. It finds 'server1' and connects to it.
3. Everytime the client wants to create an object, it sends it to the replication manager, instead of the replicas. The replication manager then creates duplicate beans in both servers.
4. The client wants to create a Host stateless session bean, so it sends the request to the replication manager, which in turn creates two identical session beans in both primary and backup servers.
5. 'server1' dies and the client gets an exception.
6. The fault detector detects that 'server1' is dead and notifies the replication manager.
7. The replication manager modifies the global JNDI accordingly.
8. The client keeps getting an exception until 'server1' is removed from the global JNDI.
9. The client looks into the global JNDI and finds that 'server1' in no longer there but 'server2' is available. It connects to 'server2'.
10. The replication manager attempts to remotely restart 'server1'.
11. Once the fault detector notifies the replication manager that 'server1' has revived, the replication manager adds 'server1' to the end of available servers list in the global JNDI.
749-Team2-Evaluation.doc (Preliminary Result)
749-Team2-Evaluation.pdf (Preliminary Result)
749_probe_data1_12.zip (RAW Probe data for configuration 1~12 (out of 48))
Finished
Failover evaluation, graph, piechart, and proposed strategies (.doc) (.pdf)
Final Report (ppt)
CODE/BINARIES (Final Demo al\
so available at /afs/ece/class/ece749/public_html/teams-06/team2/final_demo. See INSTRUCTIONS in the folder for explicit in\
structions on how to run our system.)