COMPONENTS AND TECHNICAL SPECIFICATION
Hardware Components
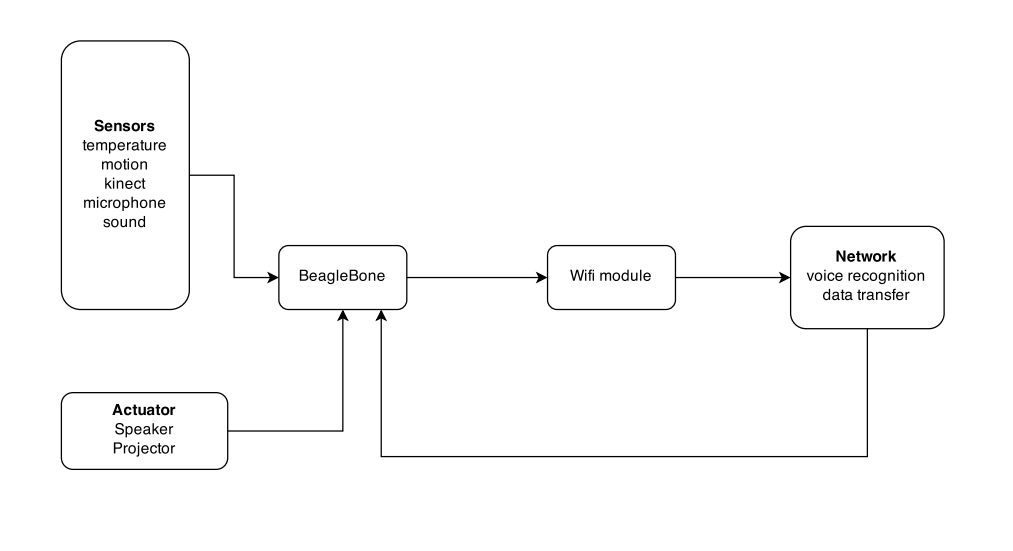
We use a microphone to collect sound input from a user and then transfer the signal to our Raspberry Pi chip. If the input sentence contains activation word "Dude", Raspberry Pi sends data to server for speaker recognition. Otherwise, it processes the command directly.
We uses temperature sensor to capture the relative humidity and temperature of the room. It uses a digital 2-wire interface and can offer high precision and excellent long term stability. The sensor will collect data continuously and send the data to the central chip. When a user query for temperature, our Raspberry Pi chip then reports temperature to user.
We uses a camera to capture ten pictures of a user's front. Then Raspberry Pi runs facial recognition locally.
We use a brightness sensor to determine whether it is dark or bright at home during the night. Further we can find out whether there is anybody at home through this information.
We use Raspberry Pi as the central chip for our project. It is interated with sensors and actuators.
The Raspberry Pi chip will gather information about user’s query and convert the result into sound signals using cloud computing. Those sound signals are going to be transmitting by speaker.
We use speaker as the actuator to guide user through making commands and feedback information.
After the user query about something through sound, the central chip will send the sound data just collected to Google voice server and wait for the respond. After the sound information is parsed into strings. The chip will either process locally (i.e. the room temperature and humidity) or search the keywords on the internet. When the result is returned, it is again passed to Google voice server to convert back into sound. Finally, the result is transmitted by the speaker.
Software Components
Protocols
A user would activate Dude recording by say "Dude" and wait for response. If it is user's first time using the device, Dude will say "I am Dude, who are you?" Then user can say "I am ..." or "My name is ..." to set up a profile with Dude. Then user can say commands. For first time use, user can also activate faical recognition by saying "recognize." User can set or cancel alarm with "Set alarm at ..." or "Cancel alarm at ...". Alarms will be propogated across other devices.
Components Annotation